TeamSpeak was not exactly on everyone’s radar when I started this research at the end of last year. But when Discord announced mandatory age verification in February, it found itself back in the spotlight rather unexpectedly1. Good timing, as it turned out. In this post I want to give a technical deep-dive on a heap use-after-free vulnerability (CVE-2026-4390) which I discovered in the TeamSpeak 3 server, published alongside other vulnerabilities in our latest advisory. I’ll cover my research approach, the root cause analysis of the bug, and how far it could be pushed towards remote code execution.
Target Overview
TeamSpeak is a proprietary VoIP application for voice and text communication. At the time of my research, two versions were available for self-hosting: the stable TeamSpeak 3 (3.13.7)2 and a beta release of TeamSpeak 6 on GitHub3. I focused on the stable Linux (x86_64) release. At the time of writing, a browse through TeamSpeak’s official hosting partner list4 shows that third-party providers either explicitly offer TS3 servers only, or advertise TS6 compatibility but without screen sharing support which suggests that TS3 is still running under the hood in most cases.
The TeamSpeak 3 server exposes several ports by default: UDP 9987 for voice communication, TCP 30033 for file transfers, and optional query interfaces on TCP 10011 and 100225. This research focused on UDP 9987, the main port for both voice and control communication.
The protocol used for communication over UDP 9987 is proprietary with no official documentation. However, after some research I found a healthy ecosystem of projects building custom TeamSpeak bots and client libraries, and with them, community-driven protocol documentation. Most notably, the “ReSpeak” GitHub organization hosts a “TS3 Protocol Paper”6 which turned out to be a surprisingly extensive resource on how the protocol is structured and how it works.
The TS3 protocol distinguishes between several packet types: voice, command, ping/pong, and a dedicated Init1 type used exclusively during the handshake. Each packet carries a fixed header containing a MAC for integrity verification, a packet ID, and a type/flags byte that controls encryption, compression, and fragmentation. Since UDP provides none of the reliability guarantees TCP does, the protocol implements its own: certain packet types require explicit acknowledgement, out-of-order packets are tracked and resequenced using packet IDs, and large payloads can be fragmented across multiple frames.
The connection process itself happens in two phases: a low-level handshake involving an RSA-based proof-of-work puzzle, followed by a high-level ECDH key exchange that establishes shared AES-EAX encryption for all subsequent communication. The handshake is concluded with the clientinit command where the client formally identifies itself.
One notable aspect of the protocol is that this entire connection handshake is necessarily exposed to unauthenticated clients and given its complexity, it represents a considerable pre-authentication attack surface worth examining.
Research Approach
Since interacting with the target required speaking a proprietary protocol, the first question was simply “where do we begin?”. I usually like to start with some hands-on interaction from a user perspective, to get a rough feel for how things work, preferably with custom scripting so I can also go off the rails here and there. Reimplementing the protocol seemed quite tedious though (even with AI) due to its complex connection handshake and timing sensitivity. So I figured it would be most efficient to approach this research iteratively. Starting with minimal effort with existing tooling and libraries and only investing more when the current approach stopped yielding meaningful results. Also, in terms of scope I primarily wanted to focus on the mentioned pre-auth attack surface as well as the connection setup and handling in general since it seemed the most interesting to me.
I began by tinkering with an existing TeamSpeak 3 bot implementation. The bot would connect to the server, play an audio file and disconnect again. Rather than building anything custom, I used the existing implementation as a handle to manipulate the protocol directly, flipping bits, modifying fields, and observing how the server responded. I proceeded with automating this setup, adding a random mutator to the implementation and wrapping everything into Docker containers to spawn and run them in batch to hopefully catch some low-hanging fruits.
While this was running for some days I started reversing the binary in Ghidra to get an initial understanding of the connection handshake and packet handlers. Obviously this was also supported by the resources discussed above. The goal was to guide the fuzzing with some structural knowledge.
I also used this opportunity to explore how LLMs could fit into my reverse engineering workflow. With Claude Mythos now making headlines for autonomously finding and exploiting zero-days in major software7 (backed by a optimised agentic scaffold running thousands of parallel instances), it is worth noting that my setup was considerably more modest, which I think is actually the more relevant data point for most people. Ghidra MCP combined with a standard Claude Opus (4.6 at the time) is accessible and affordable, and that is what I used throughout this research. AI proved most helpful when directed at specific, well-scoped tasks such as giving functions meaningful names, understanding isolated code snippets and getting a rough overview of unfamiliar code. Once the scope/context became too large, the results became unreliable. Within those boundaries though, it genuinely saved time.
One thing worth keeping in mind when using cloud-based LLMs for security research is that any code or binary snippets you share end up with the model provider. For client engagements we exclusively use locally hosted models for exactly this reason, but for this research on a publicly available binary, using a cloud-based model was a reasonable tradeoff.
As I gained a better understanding of the binary and its inner workings I abandoned the initial “remote black box” fuzzing approach and replaced it with a more efficient and targeted binary black box fuzzing using AFL++ and QEMU-instrumentation. I won’t go into detail about fuzzing in this blog post as there are already lots of great articles about the topic out there.8 For those interested: a boilerplate for the setup I used is available here9.
Just like with most research projects, the road was anything but a straight line. I kept switching between dynamic and static analysis, combined with fuzzing, gradually building up a picture of the binary’s inner workings.
Please Do Not Hack Me
After lots of manual tinkering with one of my testing clients, I noticed that the server would occasionally crash when sending one of the handshake messages twice within the handshake procedure. But the crash only seemed to occur when certain debug log lines were present in the client code. As I added and removed logging statements during development, I noticed the crash would only reproduce when the logs were in place which suggested that the additional latency introduced by the logging was slowing the client down just enough to hit a timing-dependent code path. Remove the logs, and the crash would disappear.
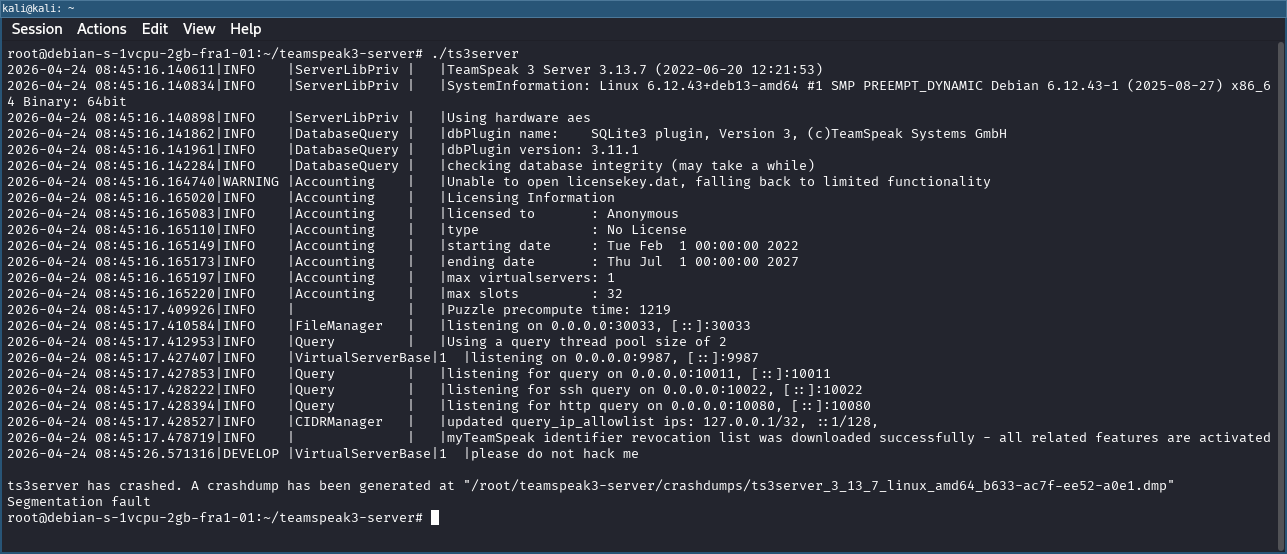
Crash with "please do not hack me" error message
Whenever the crash occurred, the server logged the message “please do not hack me” just before going down. An odd thing to find in production software. Also, I noticed that the crash occurred at different locations in the binary, but always had one thing in common: a pointer dereference gone wrong, an early indicator of a use-after-free?
Stack trace of the crash
Digging Deeper
Since the “please do not hack me” log message really caught my attention I wanted to investigate where it was coming from. The message could be traced back to the handler function for the clientinit step of the handshake, which was the one I sent twice. The conditional branch responsible for the message was entered when the handshake counter of the client connection object did not equal 2. Or in other words, when clientinit arrived at an unexpected point in the handshake sequence. Quick heads-up: decompiler output can be messy and hard to follow, so throughout this post I’ve represented most code snippets in a very simplified form or even as pseudocode to keep things readable.
| |
I noticed that reaching the else branch at all was only possible when both packets were sent within a very tight time window. Spacing them out slightly meant the second clientinit never even reached the handshake counter check. This suggests that there are earlier guards in the protocol that prevent clientinit from being processed once the handshake has already completed. The race is therefore not in the counter check itself, but earlier: both packets need to slip through those guards concurrently before either has had a chance to update the shared connection state. Once that succeeds, one packet takes the success path (handshake_counter == 2) and the other hits the error case, logging “please do not hack me” and returning error code 0x701. That said, I couldn’t directly correlate the error case to the crash.
I recalled that in my AFL++ fuzzing setup I had been using QASan (QEMU-based AddressSanitizer) to detect memory errors. I figured the same approach could give me more insight into the crash I was seeing outside of the fuzzer. So I started the ts3server binary under afl-qemu-trace with AFL_USE_QASAN set and triggered the crash with a couple of attempts.
| |
As you can see, QASan confirms a heap use-after-free. Beyond just detecting the error, it provides a useful summary of the affected chunk, where it was allocated, where it was freed, and where it was subsequently accessed after being freed. Exactly what we need to find our way back to the root cause in the decompiler.
Allocation
Let’s start with the allocation. The backtrace shows QASan’s hooked malloc at the top, followed by malloc itself, then _Znwm, which is the mangled symbol for operator.new, the C++ heap allocation operator which ultimately calls malloc under the hood, and finally 0xa1b9d1, which points us directly to the allocation site in the ts3server binary. Here’s a simplified version of the function at 0xa1b9d1.
| |
What is happening here? As mentioned earlier since the TS3 protocol operates over UDP, it implements its own reliability layer. Certain packet types require explicit acknowledgement from the receiving side. This means that whenever a packet is sent that requires acknowledgement, the connection state has to track the pending ack until it is confirmed.
The function responsible for exactly that is create_resending_packet. It allocates a ResendingInPacket and a ResendingPacket on the heap and assigns the ResendingInPacket to the ResendingPacket. Then the ResendingPacket is added to a ResendQueue and registered with the ack window of the client context, keeping track of it until the corresponding acknowledgement arrives. Don’t worry about the exact data structures for now, we will get to those shortly. The second allocation (the one of ResendingPacket) with size 0x30 is the allocation QASan reported. It’s important to note that this function is called whenever the server sends a packet to the client that expects an acknowledgement in return.
Free
Now that we know where the chunk is allocated, let’s follow QASan to where it gets freed. The corresponding function at address 0xa18aa3 which I called process_resend_queue is rather complex, so the following pseudo code summarizes the most important bits.
| |
As you can tell, process_resend_queue appears to process packets that are due for retransmission, so it’s presumably a task that runs periodically in the background. For each pending packet it looks up the associated client context and either reschedules the packet for another resend attempt, cleans up if the ack has already been received, or tears down the connection if the retransmission limit has been exceeded. In all cleanup cases, the ResendingPacket that was taken from the resend_queue gets freed. Notably, the operator.delete call reported by QASan corresponds to the case where a packet is due for retransmission but its associated client_con is NULL, meaning the client has already disconnected.
Data Structures
Let’s piece together the relevant data structures from the code we have seen so far. The resend queue is held by a global server context object, shared across all client-handling threads. As we observed above, the resend queue contains references to ResendingPacket instances, packets that have not yet been acknowledged by the client. On the other side, each client has its own client context object that holds per-connection state. Within that client context lives an ack window that references the same ResendingPacket objects. In other words, each ResendingPacket is simultaneously pointed to by two independent structures.

Relations between relevant data structures
Access of Freed Pointer
Now that we’ve understood the allocation and free, let’s turn to the third piece of the puzzle, the access of the previously freed pointer. Unlike the allocation and free, which pointed to clear and consistent locations, the crashing access was less straightforward. The faulting instruction varied across runs, which made it harder to pin down a single access site. The two functions in which the crash occurred are summarized below.
| |
process_received_ack is called when the server receives an acknowledgement from the client. It acquires the resend_queue mutex, removes the corresponding ResendingPacket from both the ack window and the resend queue, and frees both the ResendingPacket and its associated ResendingInPacket.
| |
find_and_remove_acked_packet is called from within process_received_ack and acquires a mutex on client_con. It looks up the corresponding slot in the ack window by sequence number, and if the slot is still marked as in use, clears it and returns the associated ResendingPacket pointer to the caller for cleanup.
Both QASan and manual debugging in GDB confirmed that the ResendingPacket pointer retrieved from the ack window inside find_and_remove_acked_packet is the freed pointer being accessed before the crash occurs. However, these circumstances raise the following (obvious) question: how does a pointer that was just looked up from the ack window end up pointing to already freed memory?
Let’s quickly recap what we have learned so far. The server context holds a resend queue that is populated with ResendingPacket objects for every packet sent to a client that expects an acknowledgement. Simultaneously, the client context holds an ack window that references the same objects. When an acknowledgement arrives, the corresponding ResendingPacket is removed from both the ack window and the resend queue and freed. If no acknowledgement arrives, the packet is retransmitted until a timeout is reached, at which point it is removed and the connection is torn down.
We have two data structures, the resend queue and the ack window, both holding references to the same ResendingPacket objects. Suspicious, right? However, the locking in the functions we looked at actually appears correct: the resend queue mutex acts as the outer lock, with the client context mutex acquired from within which ensures that both structures are always modified together under the same outer lock. On the surface, nothing should go wrong, so what are we missing?
The Missing Piece
It’s time to revisit our very first lead, the “please do not hack me” log message. At first glance, the branch responsible for the message did not seem directly related to the crash, the backtrace pointed elsewhere. But it seemed too much of a coincidence that the message appeared consistently every time the crash occurred.
I spent quite some time investigating what happened after the function responsible for the log message. The heavy use of vtable calls made static analysis alone difficult. The only way to reliably follow the code flow was through dynamic analysis, meaning a lot of manual stepping through instructions in GDB, setting breakpoints at suspected call sites and observing which functions were actually dispatched at runtime. Eventually I noticed that one particular function was consistently called after the log message, which looked like an error handler. The function looked roughly like this:
| |
So handle_command_error_response is called when a command results in an error during the handshake like our “do not hack me” error. It builds and sends an error response packet to the client, which internally calls create_resending_packet, adding a new ResendingPacket to the resend queue, and then calls remove_client_by_endpoint. Here the term “endpoint” simply refers to the combination of IP address and port that identifies the connected client. The error response was also observable on the client side, confirming that this code path was indeed reached.
Let’s have a closer look at the remove_client_by_endpoint function:
| |
The function clears the ack windows of the given client context if its client_id equals 0. It then removes the client context from the endpoint-based hash map held by the server context. The client context itself is managed by what appears to be a smart pointer-like construct, meaning the underlying heap memory is only freed once no further references to the object exist.
You might now be wondering what the client ID is? According to the unofficial protocol documentation5, the client ID is assigned and communicated to the client in the initserver response, the server’s reply to a successful clientinit. This means that throughout the entire handshake, up until the very last step, the client context has no assigned ID so that its client_id remains 0.
From this we can also conclude that the server keeps track of clients using a hash map indexed by the client’s endpoint. Let’s go back to the process_resend_queue function and see how the client context is retrieved for each resending packet.
| |
As you can see there must be two different hash maps, depending on the connection state a client is currently in.
| |
It’s important to note that in the main packet handler, where process_received_ack is called the same lookup mechanism is used.
From these observations we can further conclude the following: when a client initially connects it is identified by its endpoint and stored in a hash map keyed by endpoint in the server context. Once the clientinit step is successfully completed, it is added to a second hash map keyed by client ID. The clientinit handler confirms this behaviour, though I’ll omit the details here for brevity.
Putting the Pieces Together
We now have all the pieces, let’s put them together and see what really happens when triggering the vulnerability and how it unfolds.
First, a client connects to the server. The client context is added to the endpoint-based hash map. As the handshake progresses and the first clientinit packet is successfully processed, the client context is assigned a client ID and additionally added to the client ID-based hash map.
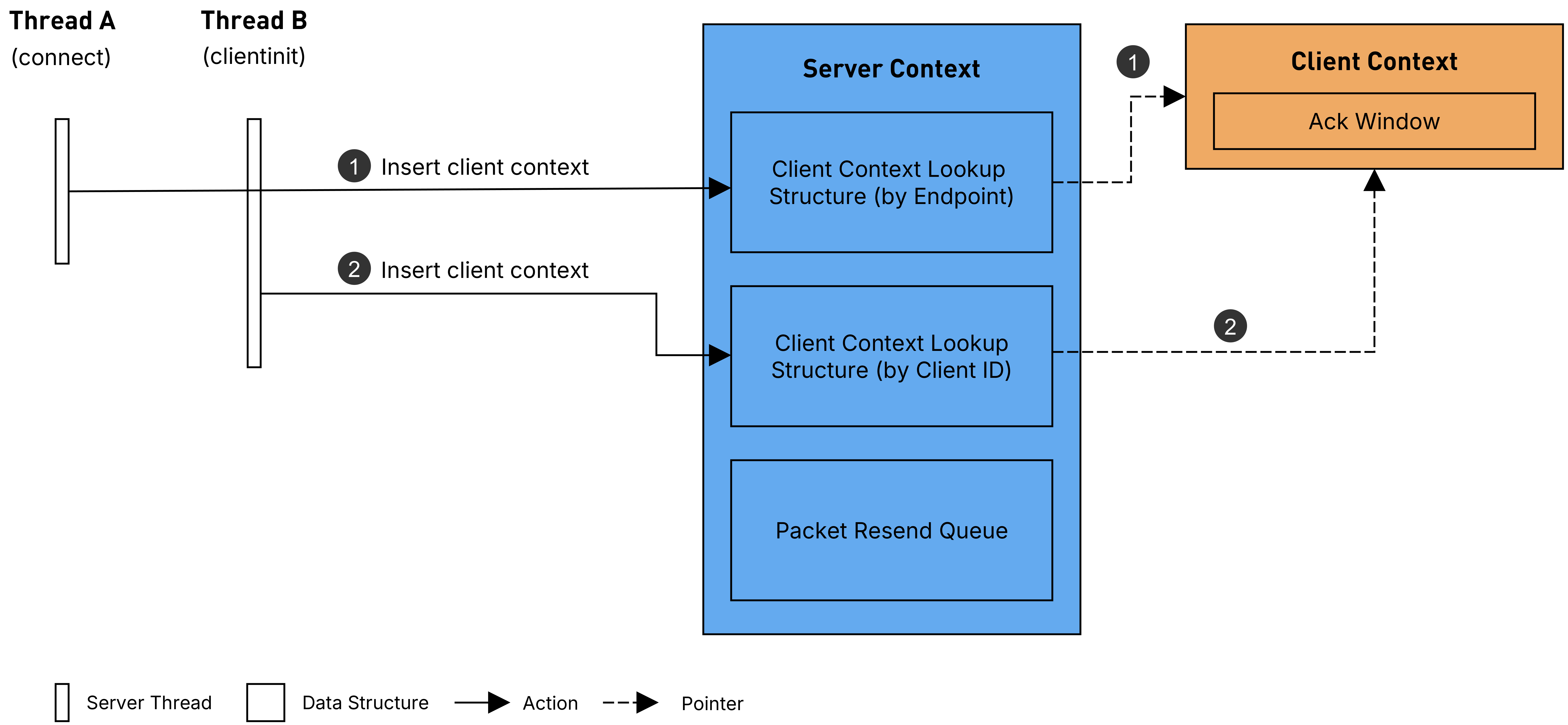
Initial connection and handshake completion
Because we send clientinit a second time, we hit the error case responsible for the “please do not hack me” log message. As discussed, this triggers an error response packet to be sent back to the client, which is added to the resend queue and the client’s ack window, and the client context to be removed from the endpoint-based hash map via remove_client_by_endpoint. Crucially, at this point in the error handler there is no awareness of a client ID, the packet is created and added to the resend queue with client_id = 0. This detail is important.
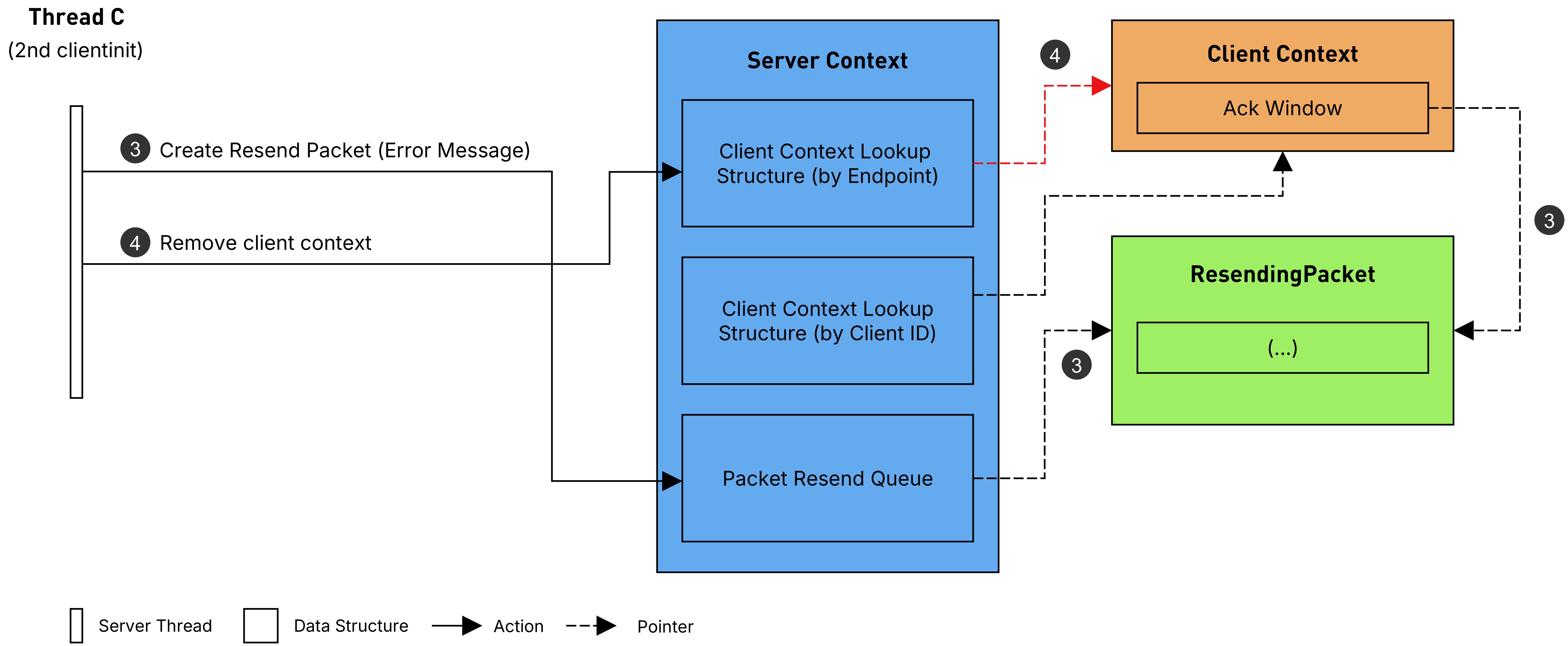
Second clientinit arrives, triggering the error handler
Next, as the client we deliberately do not send an acknowledgement for the received error message yet. This causes process_resend_queue to eventually assume the client has disconnected, because the ResendingPacket has client_id = 0 embedded, the lookup falls back to the endpoint-based hash map, where the client context no longer exists. As a consequence, the ResendingPacket and its associated objects are freed. Since no client context could be found, process_resend_queue has no way of clearing the corresponding ack window slot which leaves a dangling pointer behind in the ack window of the client context that is still referenced in the client ID-based hash map.
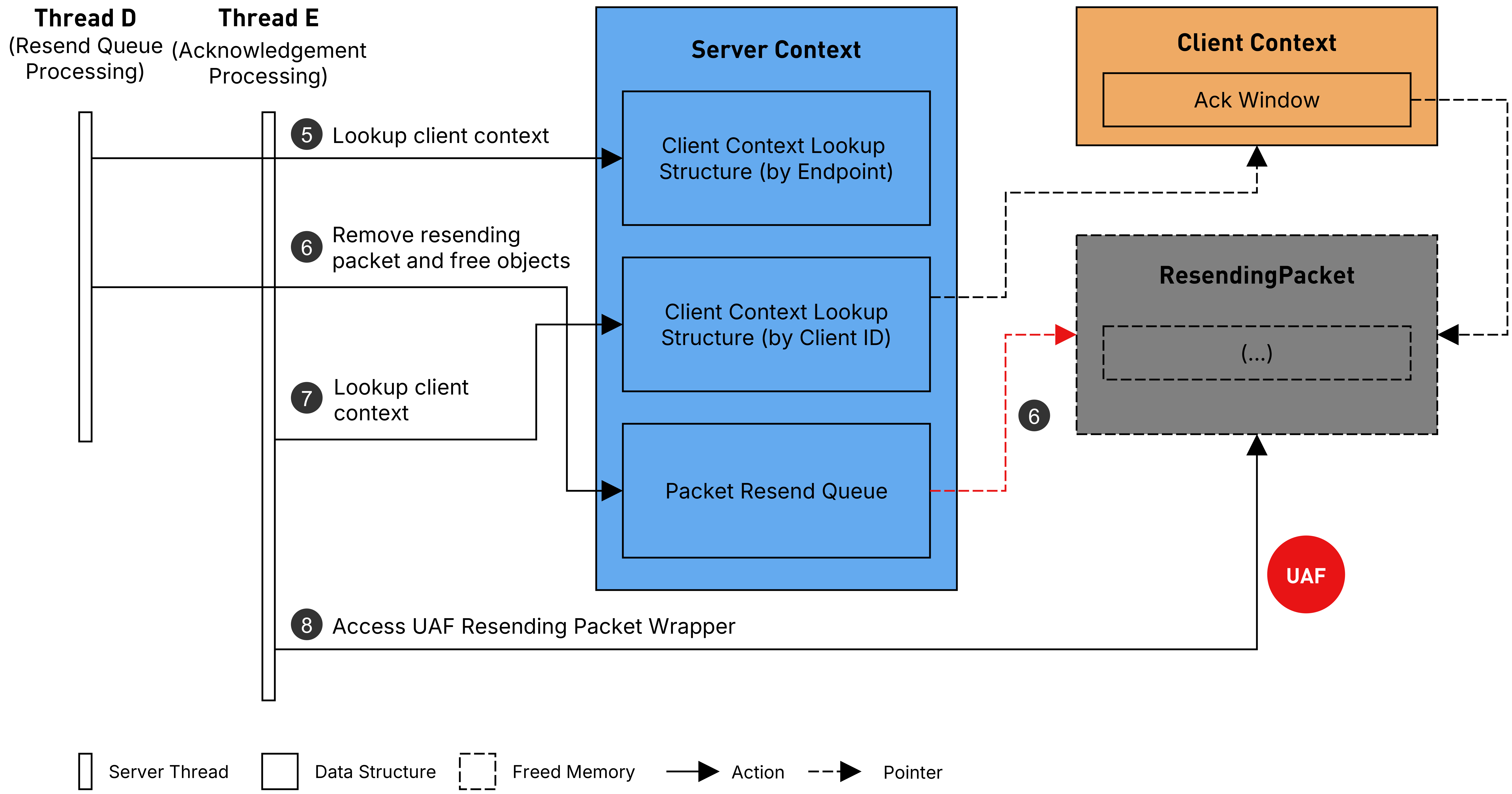
Resend queue processing frees the resending packet leading to UAF through Ack Window on acknowledgement
Finally, when we send the withheld acknowledgement for the error message, process_received_ack looks up the client context by client ID, which succeeds, since the client context is still present in the client ID-based hash map. It then retrieves the now dangling ResendingPacket pointer from the ack window and attempts to access it, resulting in a heap use-after-free.
With these insights I was able to write a reliable proof-of-concept that consistently crashes the server. The only non-deterministic part is hitting the initial race, getting both clientinit packets processed concurrently such that the handshake counter check is reached twice. In practice this race turns out to be fairly consistent to hit. Once it is, the rest of the trigger sequence is fully deterministic.
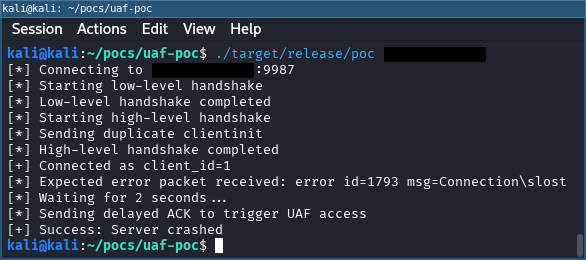
Proof-of-concept to trigger UAF condition
Beyond Denial of Service
What’s next? We have a heap use-after-free vulnerability that can be triggered remotely, but what can we actually do with it? Let’s take a closer look at what happens at the point of access. The acknowledgement handler removes the ResendingPacket from both the ack window of the client context and from the resend queue of the server context and then proceeds to free and deconstruct the ResendingPacket and its child objects. As you can see below before deleting removed_packet->resending_inpacket->inpacket a vtable call is invoked which is the deconstructor of the object.
| |
In theory, if we can get a hold of the previously freed ResendingPacket chunk on the heap, we could construct a fake object to give us a path to controlling the instruction pointer. In C++, virtual function calls are dispatched through a vtable, a table of function pointers associated with an object. When the destructor is called on the InPacket object, the program dereferences the vtable pointer stored at the beginning of the object and jumps to the corresponding entry. Looking at the data structures involved, there are several layers of indirection between the UAF chunk and the actual vtable call, the ResendingPacket points to a ResendingInPacket, which in turn points to the InPacket whose vtable is dereferenced. Crafting a fake object chain that satisfies all the intermediate field accesses is non-trivial, but conceptually not impossible.
ResendingPacket and associated data structures
It is also worth noting that the binary is not compiled with PIE, meaning no address leak would be required to redirect execution to a useful target. But the first question remains: can we reliably reclaim the freed chunk at all? The idea is to perform a heap spray, allocating many controlled chunks of the target size to increase the likelihood of one landing in the freed slot, giving us control over its contents.
A quick note on the test environment: all experiments were conducted on a standard Debian installation with the default system libc, which I considered a realistic deployment target.
Let’s first trace the lifecycle of our target chunk. The ResendingPacket of size 0x30 is allocated in a packet handler thread, one of the threads from the pool processing incoming packets, when the error response for the second clientinit is created. It is later freed in the background thread responsible for processing the resend queue.
This cross-thread free has an important implication. To understand why, a brief note on glibc’s tcache: each thread maintains its own per-thread cache of recently freed chunks, organised by size class, which allows subsequent allocations of the same size to be served quickly. Since tcache is per-thread, the freed chunk lands in the tcache of the background thread, not the packet handler thread we could potentially spray from. To get the chunk into a place we can reach, we first need to saturate the background thread’s tcache for the 0x30 size class. Once it holds the maximum of seven entries, subsequent frees of that size fall back into a location where other threads can potentially reclaim them. Saturating the tcache is achievable by opening multiple connections that trigger ResendingPacket allocations on the server side and then letting them time out, causing process_resend_queue to free enough 0x30 chunks in the background thread to fill the tcache and ensure subsequent frees bypass it entirely.
However, escaping the tcache is only half the battle. The chunk is returned to the fastbins of the heap arena it was originally allocated from, and only threads sharing that same arena can reclaim it. In a multithreaded binary like this one, glibc maintains multiple heap arenas, each a contiguous region of heap memory with its own free lists and allocator state. Rather than serializing all allocations through a single global arena, each thread is assigned its own to reduce lock contention. That said, since the original allocation happens in a packet handler thread from the thread pool, which likely shares the same arena, reclaiming the chunk from there should still be feasible. So the next question is: how do we spray effectively?
This is a question I spent a considerable amount of time on. While I did find several places where controlled allocations could be triggered, each came with its own set of problems. Reaching most of these spray primitives requires a complete handshake, which introduces a significant amount of noise on the heap, every packet handled along the way triggers numerous allocations that are beyond our control, including chunks of size 0x30, since this size class is used so frequently throughout the server’s normal operation.
It was also difficult to find primitives that would let an allocation sit on the heap long enough to be useful. For example, I found one primitive where I could freely control the size and lifetime of the allocation but not the contents, and another where I had full control over the contents but not the lifetime. Finding a primitive that satisfies all three constraints simultaneously, controlled size, controlled contents, and controlled lifetime, proved to be the main obstacle.
Unfortunately, this is where this particular journey came to an end, at least for now. At this point I have not been able to achieve reliable heap control, and therefore RCE remains unproven, though I do not believe it is out of reach. For this reason, the vulnerability was reported as a denial of service in our advisory.
Wrapping Up
In this post I walked you through my journey of researching the closed-source TeamSpeak 3 server binary. A sporadic crash, a cryptic log message, and a rabbit hole that went deeper than expected. Even without a full RCE exploit at the end, I hope you enjoyed the ride and could still take something away from this journey.
All vulnerabilities covered in our advisory were reported to TeamSpeak through responsible disclosure. We would like to thank TeamSpeak for the smooth and professional handling of the disclosure process. Along with this blog post we also decided to publish the proof of concept code for all findings here.
TeamSpeak on X - https://x.com/teamspeak/status/2022753526783312054 ↩︎
TeamSpeak Downloads - https://www.teamspeak.com/en/downloads/#server ↩︎
TeamSpeak 6 Server Beta - https://github.com/teamspeak/teamspeak6-server ↩︎
TeamSpeak Find a Hosting Company - https://teamspeak.com/en/more/find-a-host/ ↩︎
Which ports does the TeamSpeak 3 server use? - https://support.teamspeak.com/hc/en-us/articles/360002712257-Which-ports-does-the-TeamSpeak-3-server-use ↩︎ ↩︎
ReSpeak TS3 Protocol Paper - https://github.com/ReSpeak/tsdeclarations/blob/master/ts3protocol.md ↩︎
Assessing Claude Mythos Preview’s cybersecurity capabilities - https://red.anthropic.com/2026/mythos-preview/ ↩︎
Advanced binary fuzzing using AFL++-QEMU and libprotobuf - https://airbus-seclab.github.io/AFLplusplus-blogpost/ ↩︎
QEMU Blackbox Fuzzing - https://github.com/born0monday/qemu-blackbox-fuzzing/tree/main ↩︎